DreamTuner: Single Image is Enough
for
Subject Driven Generation

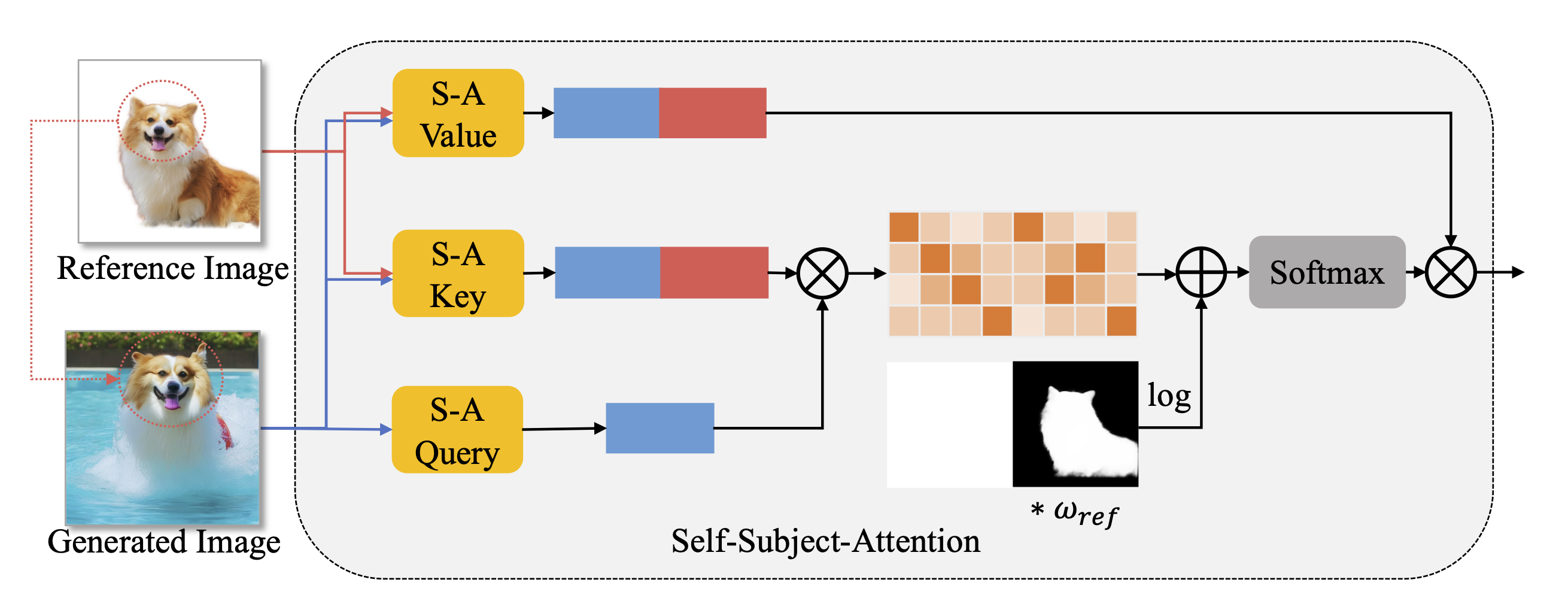
Large diffusion-based models have demonstrated impressive capabilities in text-to-image generation, and are expected for personalized applications which require the generation of customized concepts with one or a few reference images, i.e., subject-driven generation. However, existing methods based on fine-tuning necessitate a trade-off between subject learning and the maintenance of the generation capabilities of pretrained models. Furthermore, other methods based on additional image encoders tend to lose some important details of the subject due to encoding compression. To address these issues, we propose DreamTurner, a novel method that injects the reference information of the customized subject from coarse to fine. A subject encoder is first proposed for coarse subject identity preservation, where the compressed general subject features are introduced through an additional attention layer before visual-text cross-attention. Then, noting that the self-attention layers within pretrained text-to-image models naturally perform detailed spatial contextual association functions, we modified them to self-subject-attention layers to refine the details of the target subject, where the generated image queries detailed features from both reference image and itself. It is worth emphasizing that self-subject-attention is an elegant, effective, and training-free method for maintaining the detailed features of customized concepts, which can be used as a plug-and-play solution during inference. Finally, with additional fine-tuning on only a single image, DreamTurner achieves remarkable performance in subject-driven image generation, controlled by text or other conditions such as pose.
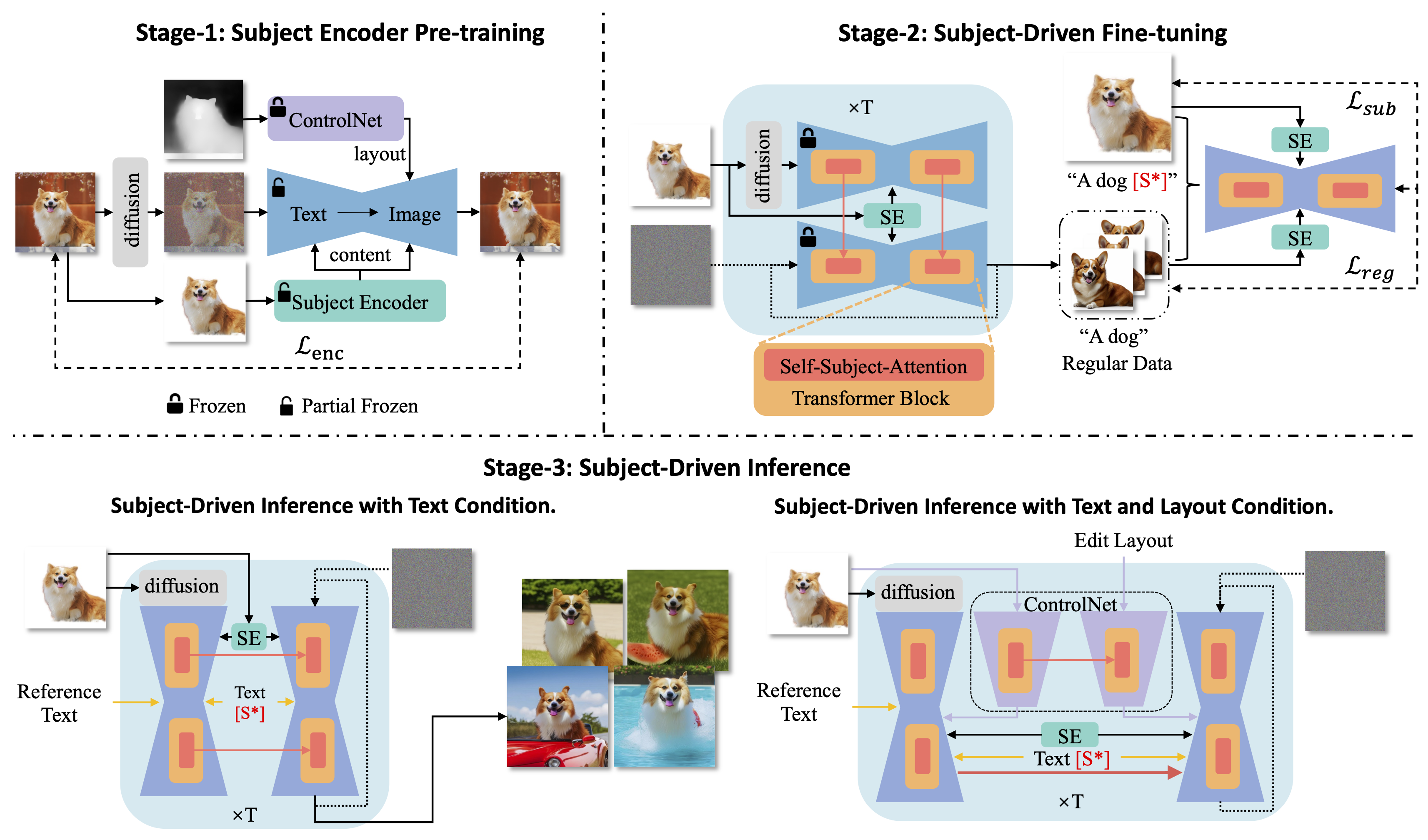
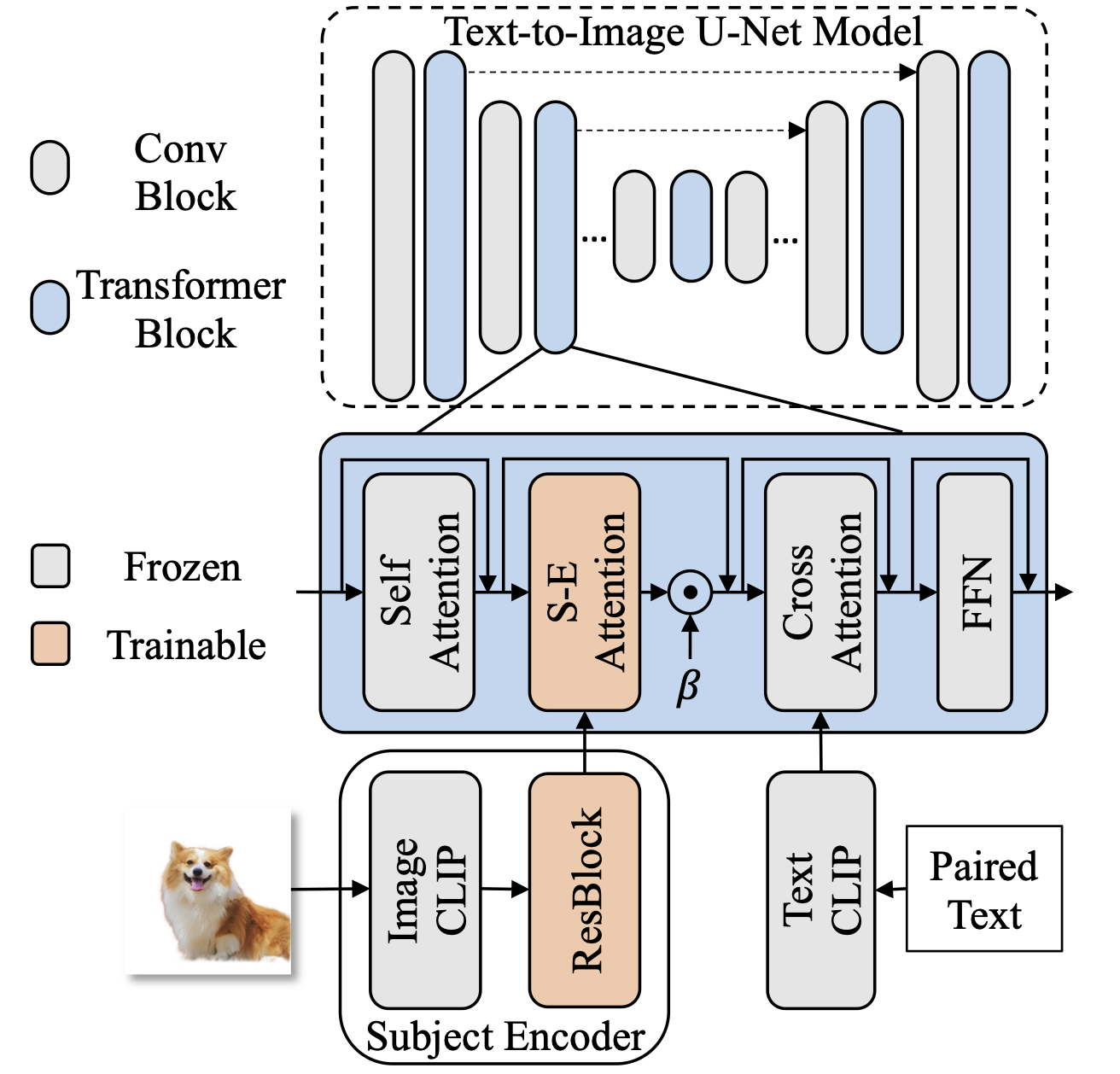
we propose DreamTuner as a novel framework for subject driven image generation based on both fine-tuning and image encoder, which maintains the subject identity from coarse to fine. DreamTuner consists of three stages: subject encoder pre-training, subject-driven fine-tuning and subject-driven inference. Firstly, a subject encoder is trained for coarse identity preservation. Subject encoder is a kind of image encoder that provides compressed image features to the generation model. A frozen ControlNet is utilized for decoupling of content and layout. Then we fine-tune the whole model on the reference image and some generated regular images as in DreamBooth. Note that subject encoder and self-subject-attention are used for regular images generation to refine the regular data. At the inference stage, the subject encoder, self-subject-attention, and subject word [S*] obtained through fine-tuning, are used for subject identity preservation from coarse to fine. Pre-trained ControlNet could also used for layout controlled generation.
The original classifier free guidance method is also modified to:
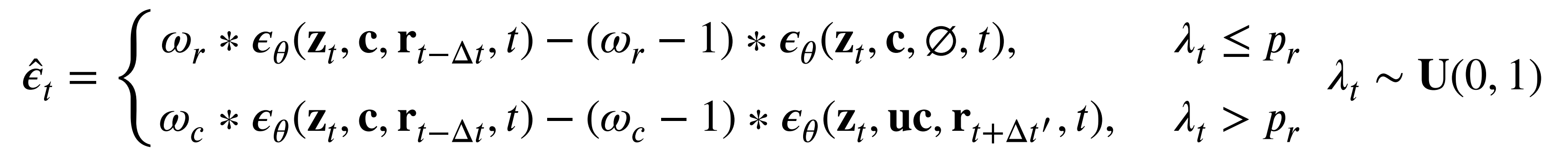
We visualize the attention maps of self-subject-attention at the middle time step (t=25) and the last time step (t=0) of generation process, with text "1girl [S*], Sitting at the table with a cup of tea in hands, sunlight streaming through the window". We choose the attention maps at the Encoder layers 7, 8 and the Decoder layers 4, 5 of Diffusion U-Net model, i.e., the layers with the feature resolution of 16*16 when the resolution of generated image is 512*512. The generated image is shown in the left and the reference image is shown in the right. The attention map appears red in areas with strong influence and blue in areas with weak influence. The red box represents the query. Some of the key attention maps at Decoder layer 5 are shown below. It can be found that the generated image will query from the reference image for refined subject information.




All of the attention maps are visualized as videos:
Our results display the output of text-controlled subject-driven image generation focused on anime characters. Both local editing (such as expression editing in the first line) and global editing (including scene and action editing in the subsequent five lines) were performed, resulting in highly detailed images even with complex text inputs. Notably, the images maintained the details of the reference images accurately.






























Our method is evaluated on the DreamBooth dataset, where one image of each subject is utilized as the reference image. Through the use of subject-encoder and self-subject-attention, a refined reference is generated, which enables DreamTuner to successfully produce high-fidelity images that are consistent with the textual input, while also retaining crucial subject details, including but not limited to, white stripes on puppy's head, logos on bag, patterns and texts on can.




























Our method can be combined with ControlNet to expand its applicability to various conditions such as pose. In the following example, only one image is used for DreamTuner fine-tuning, with the pose of the reference image utilized as a reference condition. To ensure inter-frame coherence, both the reference image and the previous frame of the generated image are used for self-subject-attention, with reference weights of 10 and 1, respectively.